A financial services platform with around 200 engineers recently set an internal rule for itself: if an engineer is writing complex branching business logic, something has gone wrong.
That sounds backwards. Writing business logic is what engineers do. But the team had watched what happens at scale when pricing rules, eligibility checks, and compliance requirements get written into application code over and over, across services and teams and years. They decided the cost was no longer acceptable. What they wanted wasn't just a cleanup. They wanted a way to enforce a single standard for how business logic gets built, and to be able to see, at any time, whether teams were actually following it.

But the deeper payoff was organizational: the change collapsed the distance between the people who define a rule and the people who implement it, letting business and engineering work on the same thing instead of trading tickets across a wall.
Here is what that restructuring involved, and why a sophisticated enterprise team concluded it was necessary.
The problem they were solving
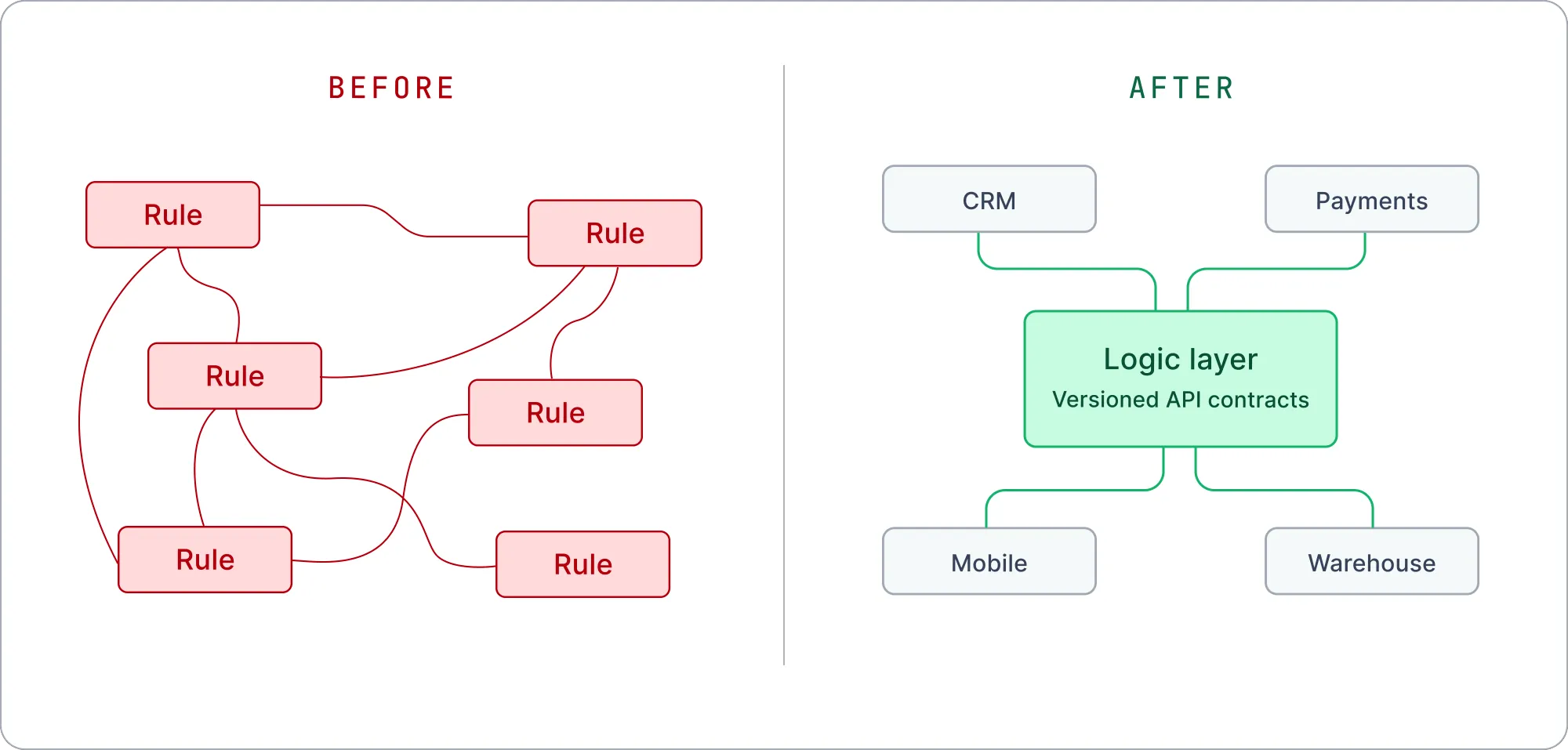
In most organizations, the rules that govern how the business actually runs do not live in any single place. The same eligibility check is implemented in three services. Pricing logic sits inside a controller. A withholding calculation is hardcoded into a workflow that was meant to be temporary. Each copy was reasonable when someone wrote it. Together they form a problem nobody chose.
There is an organizational cost layered on top of the technical one. A policy change usually starts with the people who own it—compliance, operations, a product manager—but they cannot make the change themselves. They write a ticket, it waits in a backlog, an engineer translates the intent into code, and weeks later it comes back for review. Every translation step is a chance to lose fidelity and time, and the people who understand the rule best are the furthest from where it actually lives.
The cost shows up when a rule changes. A regulation updates, and now the team has to find every place that rule was implemented. The good outcome is expensive: a multi-week investigation across a codebase no single person fully understands, ending with confidence that every instance was caught.

The bad outcome is the one that hurts. The rule gets updated in three places out of four. Nothing breaks obviously. The systems keep running, applying last year's tax rate or approving applicants who should now be declined, and stays wrong until it surfaces in a customer dispute, a failed audit, or a revenue gap no one can trace. Scattered logic makes change expensive, and it makes correctness impossible to prove. You cannot say with certainty which version of a rule is running in production, which means you cannot fully trust the answers your systems return. For a financial services company under real regulatory scrutiny, that is not a tolerable answer.
The restructuring
The move was to pull business logic out of application code and put it behind stable API contracts. Instead of a rule being implemented inside whichever service happened to need it, the rule lives in one governed place, exposed as an endpoint, and every system that needs it calls that endpoint. They built this layer in Xano.
A few decisions made it work at scale.
They kept it stateless and deterministic. No core data lives in the logic layer, and no workflows are orchestrated there. Every endpoint is a pure function of its inputs: the same input produces the same output, every time. When a decision needs data, the logic layer calls their platform services, applies the rules, and returns a clean result. The logic layer holds and executes the business rules, and that focus is what makes it auditable.
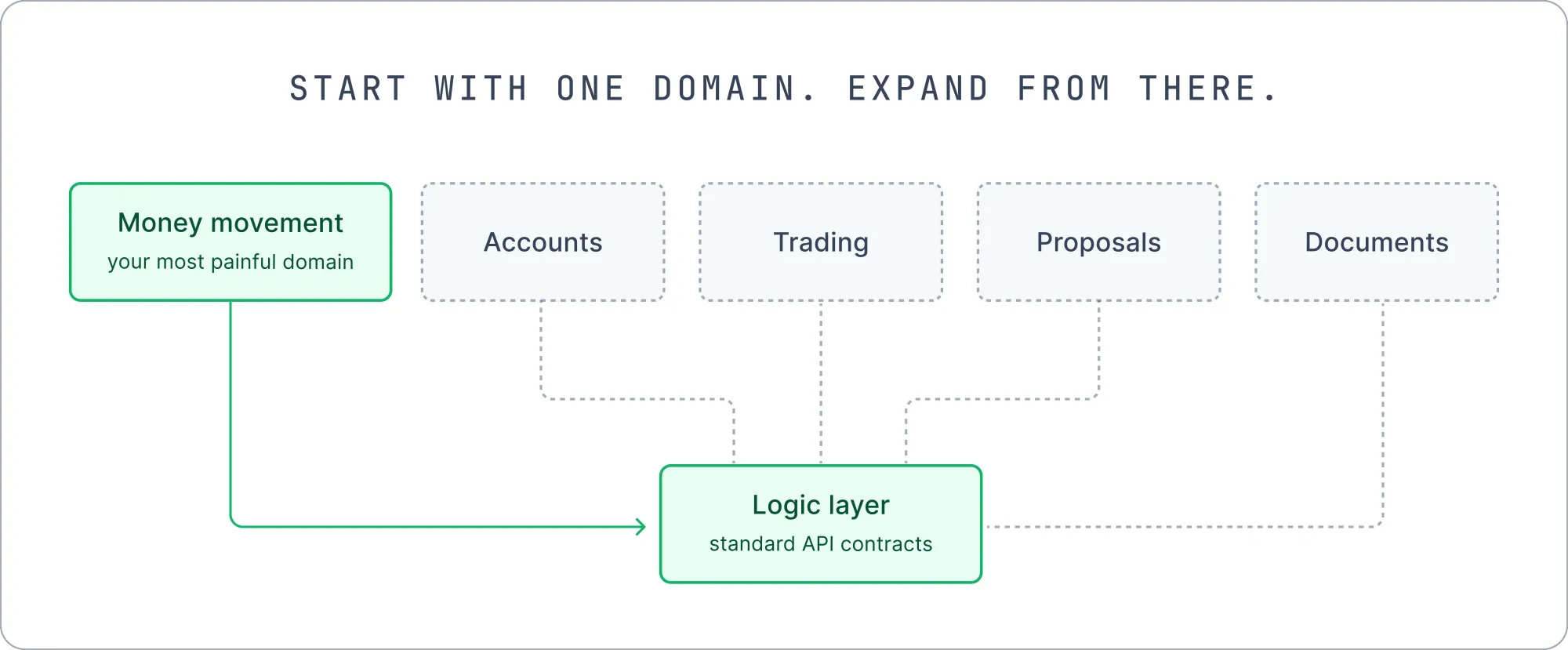
They organized logic by domain. Rather than one sprawling system, they split it into domain-level rules engines: parties, accounts, money movement, trading, proposals, documents. Each domain ships as a single versioned unit. An engineer looking for the rules that govern money movement knows exactly where they live, and changing those rules does not put unrelated domains at risk. Their vendor integrations run through the same layer, so when a third party changes their API, the change is contained in one place instead of rippling through core systems.
What changed
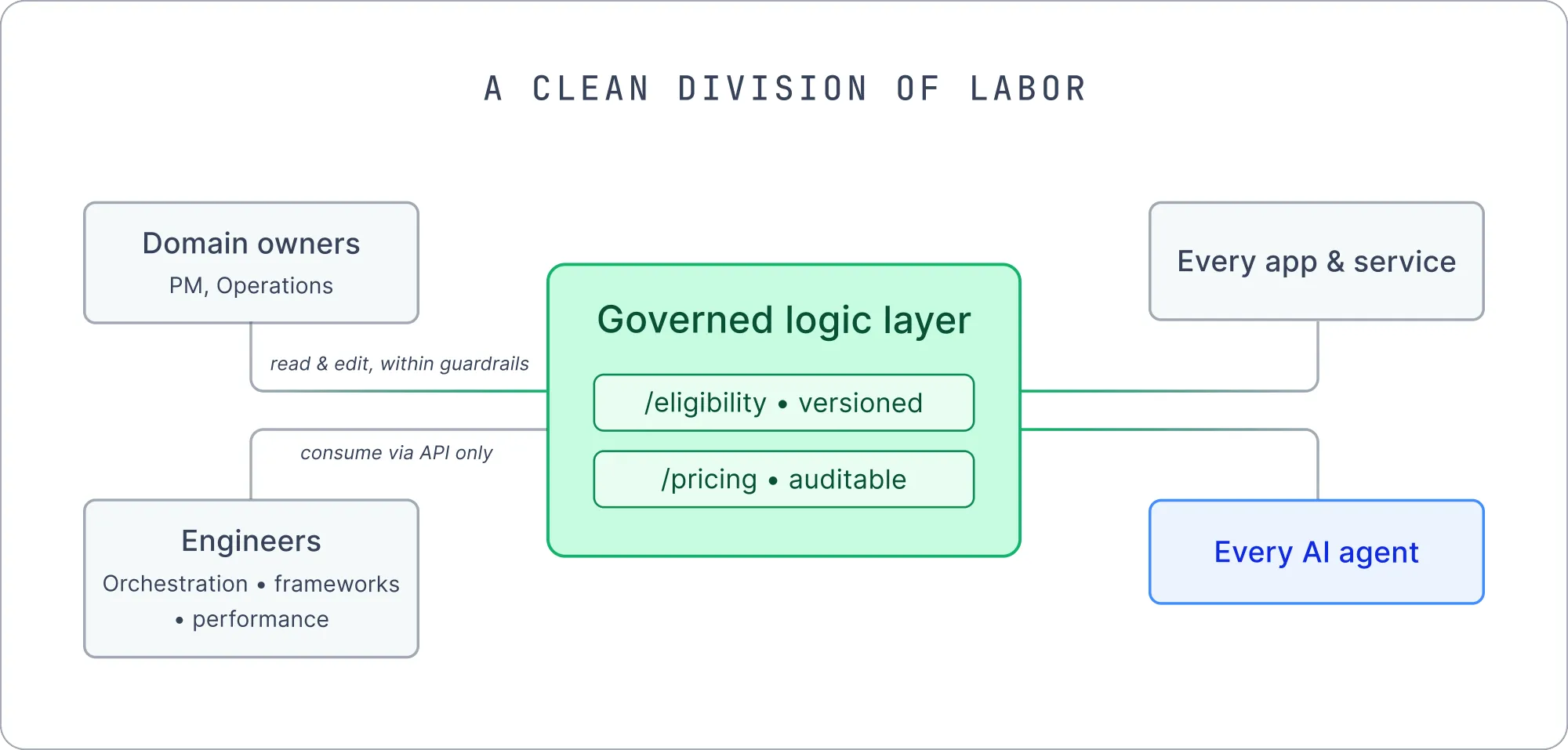
The most visible change was who can safely work on business rules. Because the logic lives in a visual, governed layer instead of inside application code, the people who own a domain (product managers, operations specialists) can read and maintain the rules that govern it, within guardrails, instead of filing a ticket and waiting for an engineer to translate a policy into code. The domain owner and the engineer are now looking at the same governed object. A product manager adjusts an eligibility threshold in the visual layer; the engineer's orchestration code keeps calling the same endpoint and inherits the change automatically. No retranslation, no sync meeting to keep two implementations aligned. This is what fusion between business and engineering looks like in practice—not a new org chart, but a shared surface that removes the translation layer between roles.
Widening who can edit business rules sounds risky, and it would be without the right foundation. The governance is what makes it safe: every change is versioned, every endpoint is auditable, and the stateless, deterministic design means a rule does exactly what it says with no hidden side effects. Governance here is not a control that limits collaboration. It is the precondition that lets the circle of people who can safely contribute grow wider.
Engineers were not sidelined; they were freed from being a bottleneck for the business and became partners to it. Both sides gain: the business moves at its own speed within guardrails, and engineering stops doing translation work it never wanted, focusing instead on the orchestration that genuinely needs its expertise. They consume the logic layer strictly through APIs and treat it as a governed, versioned dependency, which freed them to focus on frameworks, orchestration, and performance. This is what the VP meant by orchestration: when the rules have a home, engineering work becomes the assembly of reliable parts rather than the constant re-implementation of the same logic in slightly different forms.
And the correctness problem got an answer. When a rule changes now, it changes in one place, and every system calling that endpoint gets the new behavior at once. "Which version of this rule is in production" has a definite answer, because there is only one version.
Why this is more urgent than it was a year ago
This problem is not new. What changed is the speed. AI coding tools generate backend logic fast, and they almost never reference a canonical source of truth, because most organizations do not have one. An agent asked to implement an eligibility check writes its own interpretation and deposits it wherever it is working. Ask it twice and you can get two different implementations of the same rule, because the model is indeterminate by nature. The duplication that used to accumulate over years now accumulates in weeks, in places no one is tracking.
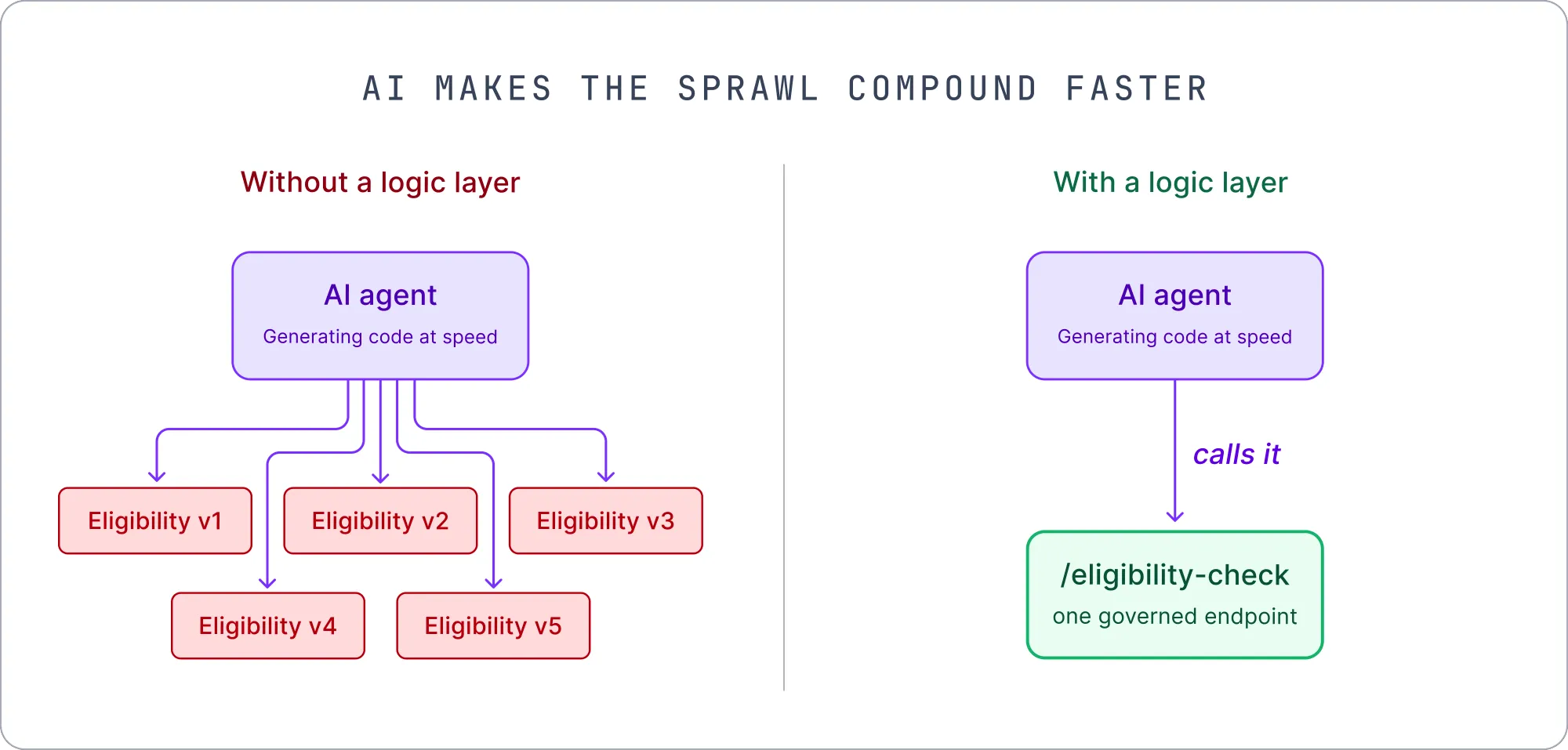
A centralized logic layer is what makes AI generation safe to adopt at speed. When the canonical rule already lives behind a governed endpoint, the agent calls it instead of inventing a new version. The teams getting the most leverage out of AI are not the ones generating the most code. They are the ones who know where their logic lives, so the new code has something correct to call. This is the fusion model paying off again: when the business owns the canonical rule and engineers own the orchestration that consumes it, an AI agent has one correct thing to call instead of generating a divergent version for each role to reconcile later.
You can do this too (and you should)
The beauty of this approach is that you don’t have to rewrite your backend to get here. The team in this story did not run a rip-and-replace migration. The logic layer sits behind standard API contracts, so consuming systems do not need to know it is there. Start with one painful domain, the rule that has bitten you most often, centralize it, and expand as the value proves itself.
If you want to better understand how this would work in your specific situation, Xano can help. Request a demo to see how a governed logic layer would fit your architecture, or try Xano for free and centralize your first domain today.