A16z's Yoko Li published a piece recently that I’ve been thinking about: The Next Frontier of Visual AI Is Code. On its surface, it's an essay about image generation (logos, UI mockups, 3D assets)—maybe not an obvious read for people as focused on backend development as we are at Xano. But the argument underneath it is one I've been making in this newsletter for months, arriving from a completely different direction. And the fact that two people looking at opposite ends of the stack are converging on the same conclusion tells me the conclusion is probably right.
Here's Li's core observation. For the last few years, visual AI has been judged by its pixels: the better the final image looked, the better the model seemed. But she argues the most interesting tools have stopped trying to generate the final output. Instead, they generate the source behind it—the SVG, the HTML, the React component, the Blender script. The pixels are still pixels at the end, but the source of truth is now a structured, editable representation. As she puts it, the model doesn't produce the final pixels; it produces the program that produces the pixels.
Why does that matter? Because of what happens after generation. A generated image is useful as an output. A generated visual program is useful as an artifact—something you can inspect, edit, version, test, and hand off. If a logo curve is wrong in a raster image, you have to mask it, regenerate it, and roll the dice again. If it's an SVG, you edit the path. Li describes the loop this unlocks: Code, render, inspect, revise. Every iteration improves the underlying artifact, not just the rendered output. The model isn't sampling more images and hoping; it's debugging a visual program in a verifiable, closed-loop environment.
Read that last sentence again and tell me it doesn't describe exactly the problem we've been talking about in backend development.
The same thesis, one layer down
Strip away the subject matter and Li's argument is this: the output is not the thing worth governing. The representation behind the output is. A picture of a chair is not a chair—it's a picture of a chair. To be useful, the artifact needs the underlying structure: the geometry, the constraints, the parts that actually behave like the thing they represent.
I've made this identical case about AI-generated backends, except the stakes are higher and the failures are invisible. When AI generates a pricing calculation, a permission model, or an approval workflow, "it runs" tells you almost nothing. The code can be syntactically perfect and still violate compliance, misroute data, or encode a business rule nobody actually intended. In the visual world, a wrong output at least looks wrong—you can see the broken curve. In the backend world, plausible-looking logic is precisely what makes the errors so hard to catch. There's no rendered image to glance at. The artifact is the only thing you have.
Which is why I find it telling where Li's essay stops. The single moment her argument reaches past drawing is one line about wiring a generated UI "into the application." That handoff—from the thing you can see to the logic that runs underneath it—is exactly where Xano lives. A16z mapped this terrain beautifully for the visual layer. The same logic, applied to backend behavior, is the entire premise of visual validation.
Code, render, inspect, revise—for logic
Look at the loop Li describes and the parallel becomes almost too neat. In her world, the renderer turns the symbolic representation into pixels, and the human inspects those pixels to decide what to fix. In ours, the visual layer turns AI-authored logic into something a human can read at a glance—where rules live, how decisions branch, which services hold authority—and the human inspects that to decide whether it matches organizational intent.
In both cases, the structured representation is what makes the feedback loop converge. In both cases, the alternative—judging only the finished output—is a dead end. Li says a reward can tell a diffusion model that one image is better than another, but it can't map feedback onto a specific source-level edit. I'd say the same thing about a passing test suite. It can tell you the code does what the spec says. It can't tell you whether the spec reflects what the business meant. Both are forms of judging the output instead of comprehending the source.
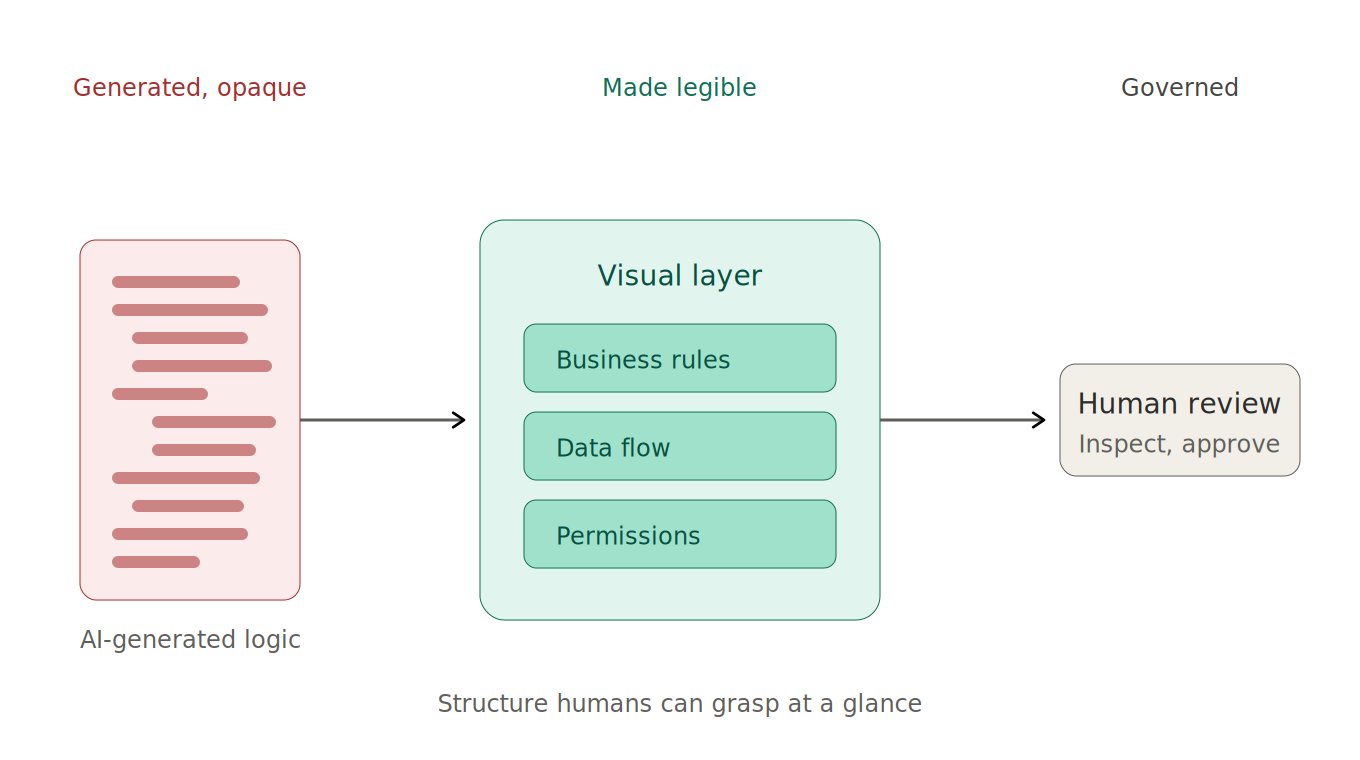
This is also why I keep insisting visual validation isn't a no-code relic or a layer of decoration on top of opaque systems. It's the same move a16z is celebrating in design tools: making the representation, not the render, the source of truth. The visual layer earns its place precisely because it is the artifact you govern—the place where a product owner verifies a pricing rule, a compliance officer checks a policy, a team lead sees how logic flows before any of it reaches production.
What the convergence tells us
When a frontier-AI thesis written about logos and 3D models lands on the same principle as a backend-governance thesis written about permission models, that's not a coincidence. It's a signal that the industry is learning the same lesson at every layer of the stack at once: as generation gets cheap, the output stops being the valuable part. The structured, inspectable, revisable representation behind it becomes the thing that matters—because it's the only thing you can actually edit, verify, and trust.
A16z calls it code-native generation. I call it visual validation. We're describing the same shift. The difference is that in the visual world, getting it wrong means an ugly logo. In the backend world, getting it wrong means a system that runs perfectly while quietly doing the wrong thing—and nobody noticing until it's in production.
Like this take on the future of software development in the AI era? Get the latest posts straight in your inbox by subscribing to the Futureproof newsletter on LinkedIn.